RFMT Clustering to Decode Customer Behaviors and Define Business Personas
Online Retail
Clustering
Customer Segmentation
Business Personas
Author
Antonio Buzzelli
Published
January 27, 2024
Abstract
In-depth analysis of customer segmentation using the RFMT model (Recency, Frequency, Monetary Value, Tenure). Employing KMeans clustering, we identify distinct customer personas and propose tailored strategic actions for each group. The study aims to enhance customer engagement, retention, and value generation through precise, data-driven marketing strategies.
Key findings and achievements
Computed RFMT features from a retail purchase dataset, for customer segmentation analysis.
Preprocessed and normalized the dataset to enable optimal clustering, and determined the most suitable number of clusters (k) using the Elbow Method.
Executed a comparative analysis of two KMeans clustering solutions, providing a clear distinction between the customer groups for k=n and k=n+1.
Interpreted each cluster to define distinct business personas, leading to the identification of strategic, customized actions aimed at enhancing customer engagement and business growth.
Introduction
In today’s competitive marketplace, leveraging data to understand and predict customer behavior is paramount for sustaining growth and securing a strategic advantage. Customer clustering analysis stands at the forefront of this endeavor, offering a powerful suite of techniques for unraveling the complexities of customer data. By partitioning customers into distinct groups, or clusters, based on shared attributes, businesses can tailor their marketing strategies, optimize resource allocation, and ultimately drive a more personalized customer experience.
The core aim of this analytical notebook is to perform an in-depth clustering analysis of retail customers, with a focus on RFMT attributes. By dissecting the nuanced behaviors captured within these features, we aspire to unearth distinct customer segments that can reveal targeted opportunities for enhanced marketing engagement, optimized product placement, and improved customer lifetime value.
Loading the data
The dataset we are utilizing for this exercise is a classic example of transactional data commonly encountered across various business sectors. It represents purchase data from an online retail business based in the UK. Each record in this dataset corresponds to a single purchase transaction made by a customer. This type of dataset is ubiquitous in the business world, providing invaluable insights into customer behavior.
The columns include basic transactional elements like Invoice number, StockCode, product Description, Quantity, and Amount of items purchased, InvoiceDate, Price of the items, CustomerID, Country of purchase, and the Year of the transaction.
Computing Recency, Frequency, Monetary Value, and Tenure
The RFMT model is a cornerstone of customer value analysis, providing a multifaceted framework to quantify and understand customer behavior. In this phase of our analysis, we will compute the four key metrics that comprise the RFMT model:
Recency (R): The freshness of customer engagement, measured by the time since the last transaction. This metric helps us understand which customers have interacted with the business recently, indicating an ongoing relationship.
Frequency (F): The rate of transactions, determined by the number of purchases made within a specific period. This dimension allows us to identify the most engaged customers who transact with the business regularly.
Monetary Value (M): The total spend of a customer, calculated by summing up the value of all purchases. This metric highlights the customers who contribute the most to revenue and can indicate potential for future profitability.
Tenure (T): The length of time a customer has been with the business, defined from their first purchase to the present. Tenure provides insight into customer loyalty and the long-term value of customer relationships.
By computing these RFMT metrics, we will transform our raw transactional data into actionable insights, segmenting customers into groups that reflect varying levels of engagement and value to the organization. This stratification enables targeted marketing efforts, efficient allocation of resources, and the development of tailored customer retention strategies. In practice, we will calculate these metrics by aggregating transaction data at the customer level, ensuring that each customer’s profile is accurately represented by their shopping habits and interactions with the business.
The recency and tenure calculations will require us to establish a reference point — typically the date of analysis or the latest date in the dataset — to gauge the time elapsed since the last transaction and the duration of the customer relationship, respectively. Frequency will be assessed by counting the number of transactions per customer, and monetary value will be ascertained by summing the total spend per customer. The process will involve data manipulation and the use of aggregate functions to ensure precise and meaningful calculations.
Ultimately, the RFMT analysis will not only differentiate customers by their transactional behavior but also serve as the basis for applying clustering algorithms. The outcome will be a set of clearly defined customer segments, each with its own distinct characteristics based on these four critical dimensions. These segments will then inform a range of strategic initiatives designed to enhance customer engagement and optimize business outcomes.
First, we define a snapshot date – a simulated point in time when we run the analysis. In our case it will be represented by the last date available in the dataset.
Then we group the data by customer ID and aggregate by:
Recency as the number of days since the last purchase for each customer.
Frequency as the number of purchases made by each customer.
MonetaryValue as the total amount spent by each customer.
Tenure as the number of days each customer has been active.
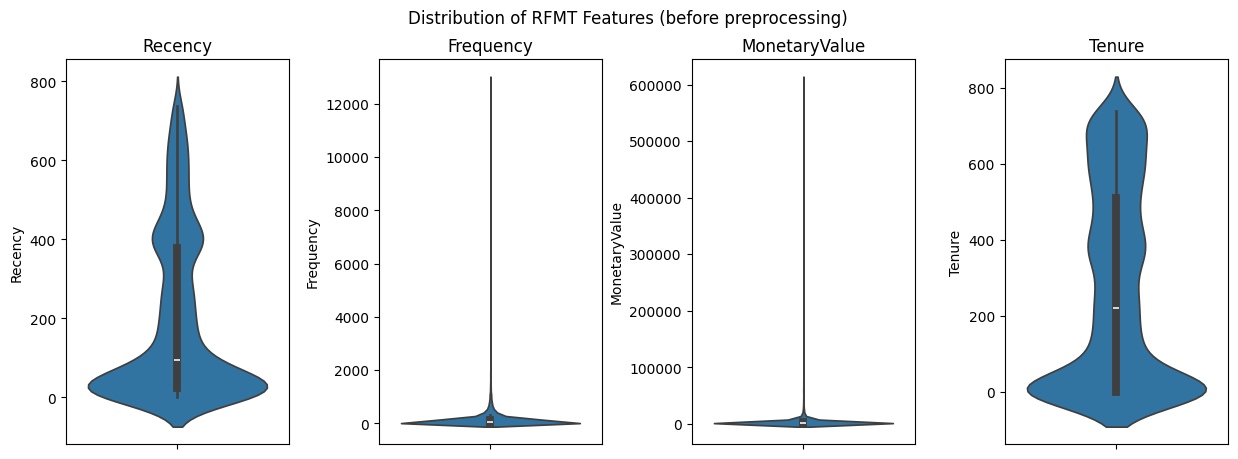
A quick analysis of the resulting features shows us that:
The average time since the last purchase across all customers is roughly 200 days, suggesting a moderate level of recent engagement. The standard deviation is substantial at approximately 209 days, indicating variability in customer engagement. The quickest repeat purchase occurred on the same day, while the longest time since a previous purchase extends to 738 days.
Customers have made an average of 137 transactions, which is quite diverse as reflected by a high standard deviation of around 354. The frequency of purchases ranges from a single transaction to a high of 12,890, showing that there are both one-time and extremely frequent shoppers in the dataset.
The mean monetary value spent by customers is $3,018.62, but with a very high standard deviation of $14,737.73, this suggests a significant spread in the total spend per customer. The minimum spend is $2.95, indicating at least one very low-value purchase, and the maximum spend is an outlier at $608,821.65, which points to high spending customers.
The average length of the relationship between the customers and the company is 273 days, with a standard deviation of about 259 days, reflecting a wide range in the duration of customer relationships. The tenure ranges from new customers (0 days) to those with relationships as long as the oldest transaction in the dataset (738 days).
The first quartile (25%) indicates that 25% of customers have interacted with the company within the last 25 days, have a transaction count of 21 or fewer, have spent no more than $348.76, and at least 25% are either new customers or have no recorded tenure.
The median (50%) shows that half of the customers have made a purchase within the last 95 days, have a transaction count of 53 or less, and have spent no more than $898.91, with a tenure of up to 220.5 days.
By the third quartile (75%), 75% of customers have recency scores as high as 379 days, have made up to 142 transactions, have spent as much as $2,307.09, and have a tenure of up to 511 days.
The high standard deviations for Monetary Value and Frequency suggest a significant variance in customer spending and engagement, which could indicate a diverse customer base with varying levels of loyalty and value to the company.
Clustering
With the RFMT metrics serving as a multi-dimensional profile for each customer, we are now equipped to apply clustering algorithms to segment our customer base into meaningful groups. This subsequent clustering is pivotal, as it aims to reveal the intrinsic patterns and similarities between customers that are not immediately apparent.
The clustering process will employ the K-means algorithm, a widely recognized method for its simplicity and effectiveness in partitioning data into k distinct clusters. The algorithm iterates through the dataset, optimizing the positions of the centroids and assigning each data point to the nearest cluster, based on the minimum distance principle. The selection of the optimal number of clusters, k, is of paramount importance and will be informed by the Elbow Method and the Silhouette Score. These metrics will guide us to a value of k that balances within-cluster homogeneity and between-cluster separation, ensuring that our clusters are both statistically significant and practically interpretable.
Preprocessing
In preparation for clustering, our dataset requires preprocessing to shape the data into a form amenable to the algorithms we intend to use. Two critical steps in this preprocessing pipeline are log transformation and standardization, particularly relevant when dealing with RFMT data, which often contains skewed distributions and features of varying scales (as we see here below).
Log Transformation The RFMT metrics—especially monetary value and frequency—can exhibit right-skewed distributions, where a small number of high-value customers distort the overall picture. To mitigate this and to normalize the distribution of these attributes, we apply a log transformation. Log transformation dampens the impact of outliers and reduces skewness, making the underlying patterns more apparent and suitable for clustering.
Before applying the log transformation, we must ensure that there are no zero or negative values in the dataset, as the log function is not defined for these numbers. In such cases, we can add a constant (like 1) to all values to make the transformation feasible.
Standardization Post log transformation, we perform standardization of the features. Standardization involves rescaling the data so that it has a mean of zero and a standard deviation of one. This is particularly important for distance-based clustering algorithms like K-means, which are sensitive to the scale of the data. If the features are on different scales, one feature might dominate the distance metric, leading to biased clusters.
By standardizing the features, we give each one equal weight in the clustering process. For RFMT data, this ensures that recency, which might be on the scale of days, is just as important as monetary value, which could be several orders of magnitude larger in raw units.
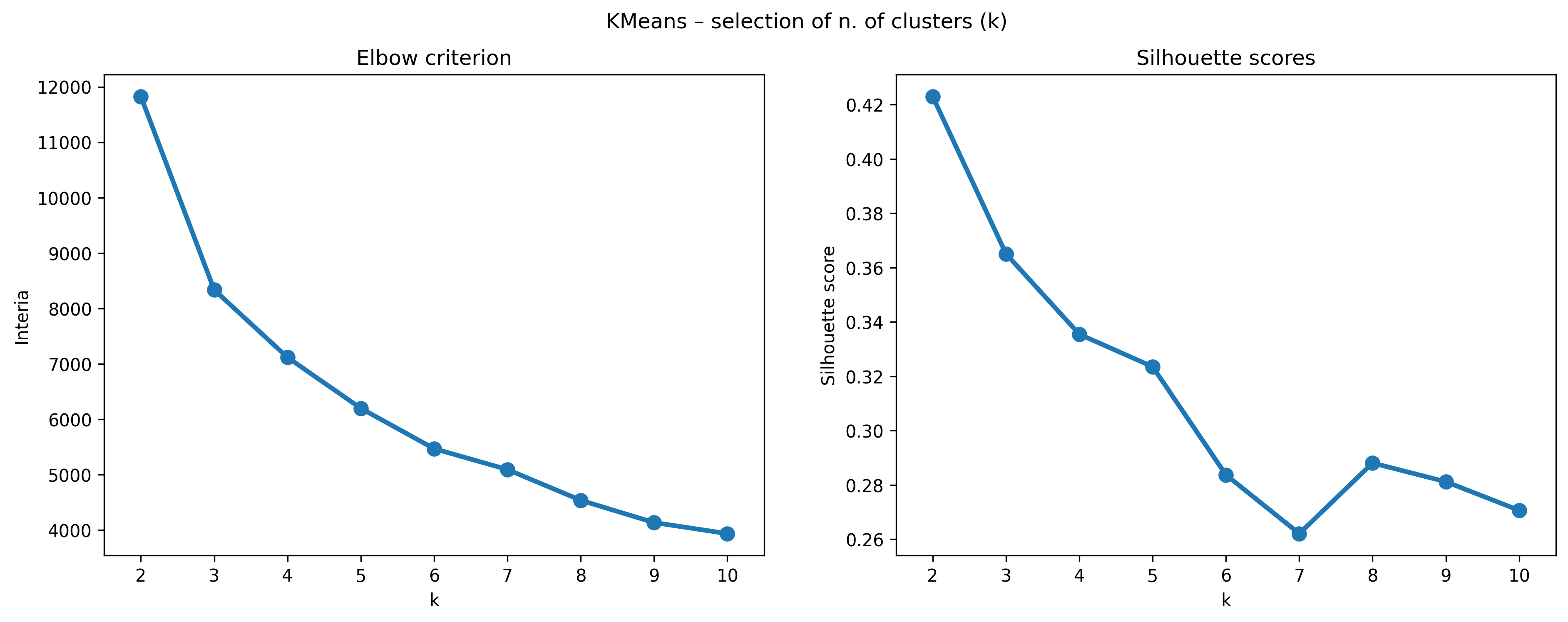
To identify the optimal k – meaning the number of clusters in which we want to group our customers –, we use two primary methods: the Elbow Method with inertia as the metric, and Silhouette Scores.
Elbow Method: In this approach, we plot the inertia against the number of clusters. Inertia, which is a measure of the total distance of points from their respective cluster centroids, typically decreases as we increase the number of clusters. However, the rate of decrease sharply changes at a certain point, forming an ‘elbow’ in the plot. The optimal number of clusters is often considered to be at this ‘elbow’ point, where adding more clusters doesn’t give much better modeling of the data. This method is intuitive and helps in visualizing the trade-off between the number of clusters and the compactness of the clusters.
Silhouette Scores: To complement the Elbow Method, we also use Silhouette Scores, which provide a quantitative measure of how well each object lies within its cluster. A high Silhouette Score suggests that the object is well matched to its own cluster and poorly matched to neighboring clusters. By evaluating the average Silhouette Score for different values of k, we can more accurately determine the number of clusters that optimally represents our data.
The combination of the Elbow Method using inertia and Silhouette Scores allows for a more comprehensive and reliable determination of the optimal number of clusters in our RFM customer segmentation. This dual approach ensures that we achieve a balance in our clustering model, avoiding both over-segmentation and under-segmentation.
From the Elbow criterion graph, the optimal number of clusters k is typically chosen at the point where the inertia (sum of squared distances within clusters) begins to decrease more slowly, indicating diminishing returns on the distinctness of additional clusters. In the graph, there is no pronounced ‘elbow,’ but there seems to be a slight leveling off after k=4, suggesting that increasing the number of clusters beyond 4 yields smaller gains in compactness.
The Silhouette score provides a measure of how similar an object is to its own cluster compared to other clusters, with higher values indicating better-defined clusters. From the Silhouette scores graph, the score tends to decrease as k increases, which is expected as more clusters can lead to less cohesion within clusters. There is a noticeable uptick at k=5, but the score is still lower than for k=2, k=3, and k=4.
Combining insights from both the Elbow method and the Silhouette scores, k=4 seems to be a reasonable choice for the optimal number of clusters. At this point, the inertia has not yet flattened out completely, and the Silhouette score, while not the highest, is relatively strong compared to higher k values. Therefore, k=4 could be considered a good balance between cluster distinctness and cohesion for this dataset.
But for the purpose of thorough analysis, we will conduct a comparison between k=4 and k=3. This comparison will help us to critically evaluate both statistical and practical aspects of the clustering results. By thoroughly investigating these two potential solutions, we will be able to determine which clustering solution is more appropriate for our customer segmentation.
Predictions
We are going now to fit the KMeans algorithm with k=3 and k=4, and append the cluster predictions both to the original and scaled rfmt datasets.
rfmt_k = rfmt.copy()k_cols = []for k in [3, 4]: model = KMeans(n_clusters=k, random_state=1, n_init='auto') col_name =f'k{k}' rfmt_k[f'k{k}'] = model.fit_predict(scaled_rfmt) k_cols.append(col_name)scaled_rfmt_k = pd.concat([scaled_rfmt, rfmt_k.iloc[:, 4:]], axis=1)rfmt_k
Recency
Frequency
MonetaryValue
Tenure
k3
k4
CustomerID
12346.0
325
34
77556.46
400
1
1
12347.0
1
253
5633.32
402
1
1
12348.0
74
51
2019.40
362
2
2
12349.0
18
175
4428.69
570
1
1
12350.0
309
17
334.40
0
0
0
...
...
...
...
...
...
...
18283.0
3
986
2736.65
654
1
1
18284.0
431
28
461.68
0
0
0
18285.0
660
12
427.00
0
0
0
18286.0
476
67
1296.43
247
2
2
18287.0
42
155
4182.99
528
1
1
5878 rows × 6 columns
Model comparison and interpretation of the clusters
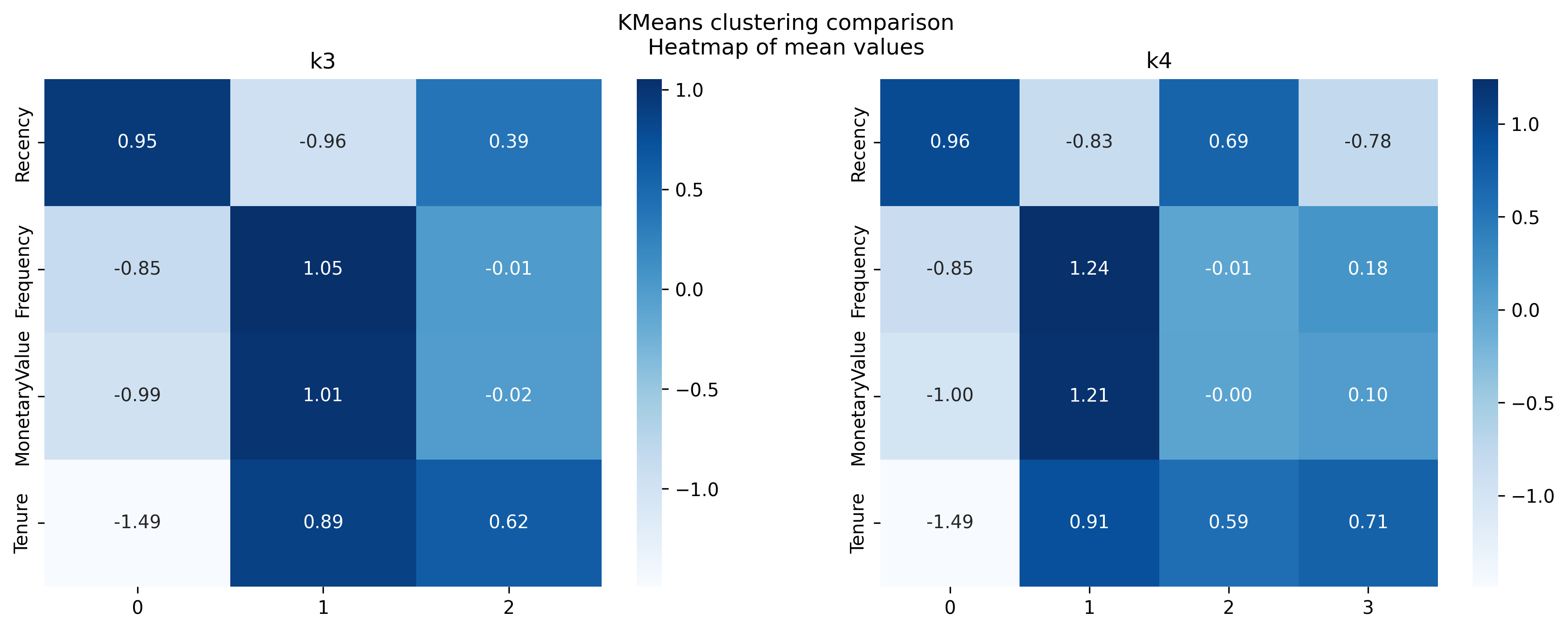
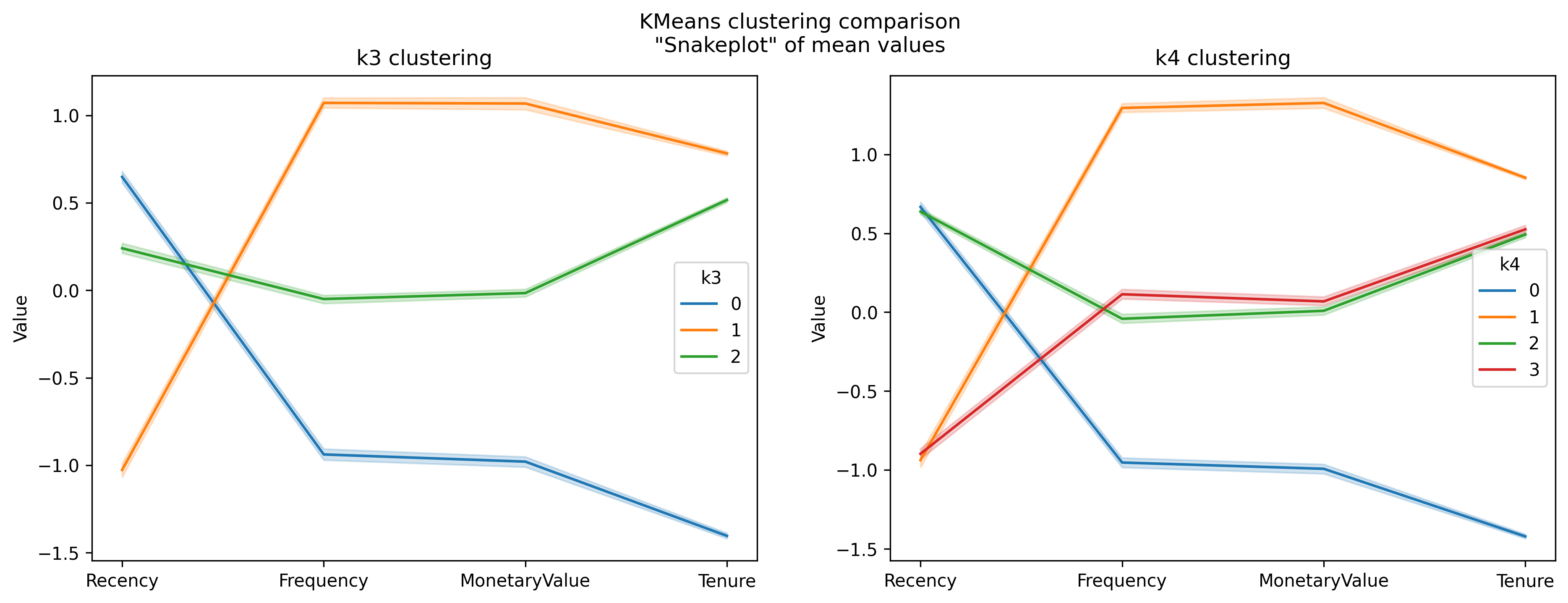
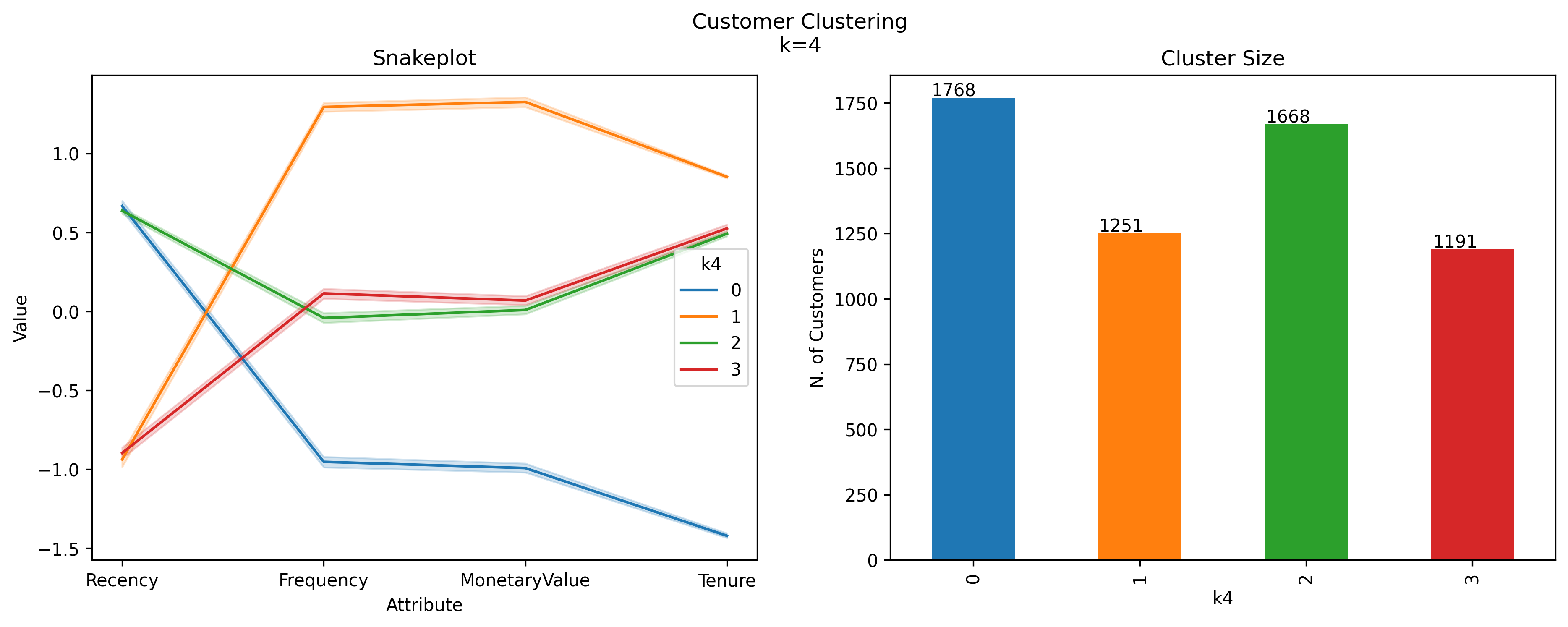
In the subsequent analysis, we will delve into the interpretation of customer clusters as delineated by the KMeans clustering algorithm for k=3 and k=4, leveraging both heatmap and snakeplot visualizations. These visual tools are instrumental in uncovering the nuances of customer behavior across different segments. The heatmaps provide a clear, immediate visual representation of the mean values of the RFM (Recency, Frequency, Monetary value) metrics and Tenure for each cluster, highlighting patterns through color intensity — darker shades indicate higher mean values within a cluster relative to others. In contrast, the snakeplots will allow us to understand the relative positioning of each cluster along the RFM and Tenure dimensions through a line plot, offering a more detailed and comparative view of the clusters’ profiles. This juxtaposition of visual techniques will enable us to draw a comprehensive picture of the clusters, identify key characteristics that define each segment, and infer the strategic implications for targeted marketing actions.
Model comparison
When comparing the clusters between k=3 and k=4, it’s evident that the introduction of a fourth cluster (the red cluster in k=4) provides a finer segmentation of the customer base, specifically related to the green cluster (of k=3).
Interpretation of clusters
Having established that the k=4 model offers a more granular and insightful segmentation of the customer base, let’s proceed with a detailed interpretation of each cluster and propose targeted actions for each.
The following table summarizes the clusters’ features and proposes related business personas.
Cluster
Recency
Frequency
MonetaryValue
Tenure
Size
Business Persona
0
High
Low
Low
Low
Large
New Potential Customers
1
Low
High
High
High
Medium
Loyal High-Value/Engagement Customers
2
High
Medium
Medium
Medium
Large
At-Risk Medium-Value/Engagement Customers
3
Low
Medium
Medium
Medium
Medium
Loyal Medium-Value/Engagement Customers
New Potential Customers (Cluster 0)
Description: This large cluster consists of recently acquired customers with low frequency and monetary value, and with no recent interactions.
Actions: Implement a nurturing strategy to foster these new relationships. Introduce onboarding programs, provide educational content, and send tailored promotions to encourage repeat purchases and increase monetary value.
Loyal High-Value/Engagement Customers (Cluster 1)
Description: A medium-sized group of customers with high frequency, monetary value, and tenure, showing strong loyalty and engagement.
Actions: Develop retention programs with exclusive rewards, recognize loyalty milestones, and offer referral incentives. Engage them with personalized communication and consider involving them in product development feedback loops to maintain their high engagement.
Description: Another large cluster, these customers have medium values for frequency, monetary value, and tenure but have engaged less recently. They might be at-risk of churn.
Actions: Reactivate these customers with “we miss you” messages, offering updates on what they’ve missed. Provide incentives that encourage them to revisit and transact, such as limited-time offers or exclusive previews of new products.
Description: A medium-sized cluster with low recency but medium frequency, monetary value, and tenure, indicating constant engagement.
Actions: Design engagement campaigns highlighting new offerings or loyalty rewards. Conduct surveys to understand their recent interaction and potential risks. Offer incentives for increased frequency and spending.
Each cluster requires a tailored approach that aligns with the behavior patterns identified through the RFM and Tenure analysis. The goal is to enhance customer value across all segments, whether by nurturing new relationships, retaining valuable customers, or re-engaging those showing signs of decreasing engagement. By taking these specific, data-driven actions, the business can optimize its marketing efforts and improve the overall customer lifecycle value.